
Comment se préparer à interagir avec une intelligence artificielle ?

L’intelligence artificielle apporte son lot de bienfaits et de méfaits. Mais quel est son vrai visage ? Une étude approfondie des algorithmes les plus en vue, de Google à Uber en passant par Watson, Siri, Alexa (Amazon) ou Google Assistant, dresserait sans-doute un état des lieux alarmant. L’heure est grave! Il convient de reprendre la main avant qu’il ne soit trop tard. La construction d’une matrice, destinée à échafauder le meilleur scénario de collaboration entre l’homme et la machine, reste à inventer. Pour l’heure, en voici une première ébauche.
L’homme doit désormais apprendre à collaborer avec la machine
L’intelligence artificielle est désormais partout. Elle envahit nos vies. Inutile de résister. Il est préférable de faire alliance avec la machine pour tirer le meilleur de notre future collaboration avec elle. Rappelons que les premiers enseignements tirés permettent déjà de dégager quelques conclusions encourageantes : l’homme peut progresser au contact d’une intelligence artificielle, l’homme et la machine pourraient s’avérer très complémentaires, nous ne sommes que dans l’enfance de l’intelligence artificielle, les machines devraient pouvoir de plus en plus s’adapter à nous, etc… Cependant, l’intelligence artificielle charrie également son lot de désastres : destruction d’emplois, ingérence dans nos vies, non-respect de la vie privée, interférence dans la vie politique, amplifications de fake news, création de richesse au détriment de la prospérité, nouvelles formes d’insécurité, extension de la criminalité…
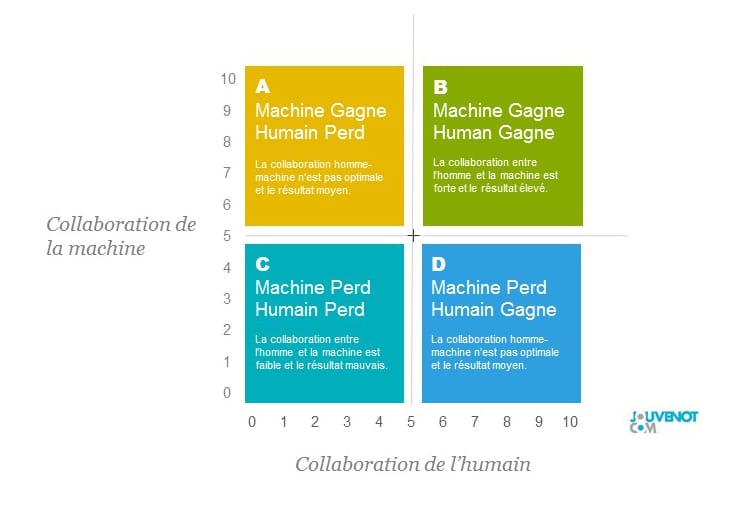
La Matrice de la collaboration homme-machine
Puisqu’il est entendu que nous devrons tôt ou tard, bon gré mal gré, coopérer de plus en plus avec des robots (nous entendons par robots tout ce qui a trait à l’intelligence artificielle, aux algorithmes, aux avatars, aux assistants vocaux, aux bornes intelligentes, à la robotique…), il est temps de tracer à grands traits les bases d’une nouvelle matrice à même de nous guider, de nous éclairer et de nous permettre de garder le contrôle de cette future collaboration.
Deux axes clés
Si l’homme et la machine doivent collaborer en vue de mettre en synergie leurs forces, leurs capacités et leurs atouts respectifs, deux axes peuvent être tracés :
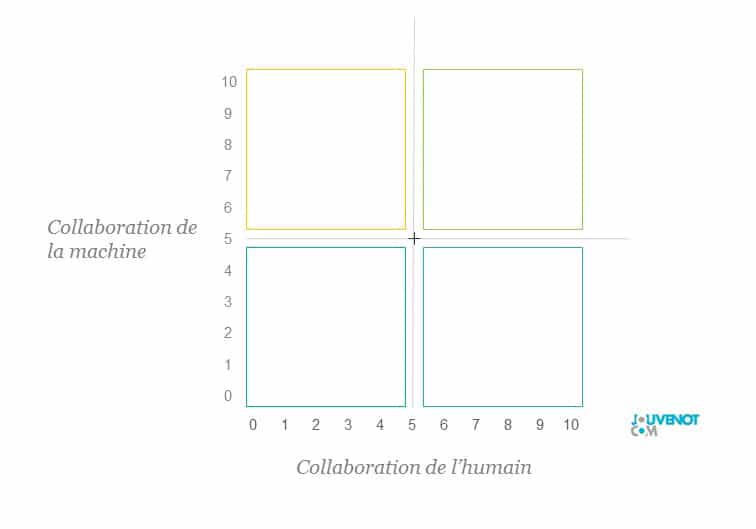
En abscisse, un axe représentant le niveau de collaboration de l’homme avec la machine. Plus la collaboration est élevée, plus l’algorithme étudié sera positionné à droite.
En ordonnée, un axe représentant le niveau de collaboration de la machine avec l’homme. Plus la collaboration est élevée, plus l’algorithme sera positionné vers le haut.
Quatre configurations possibles
Il en ressort quatre scénarios possibles.
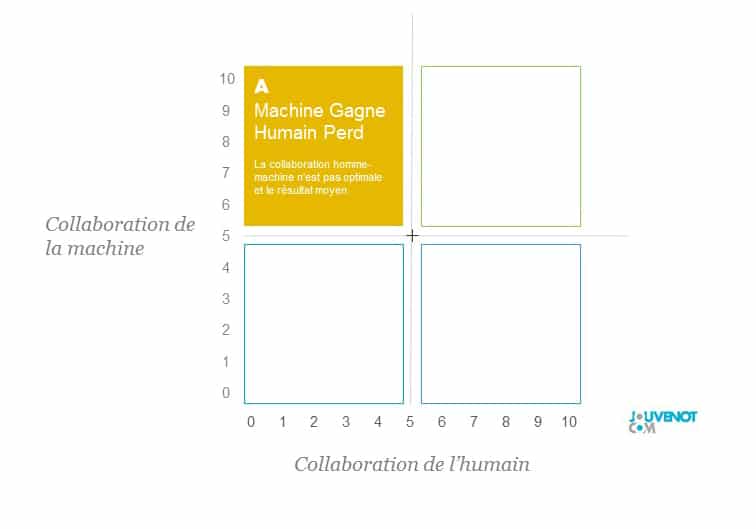
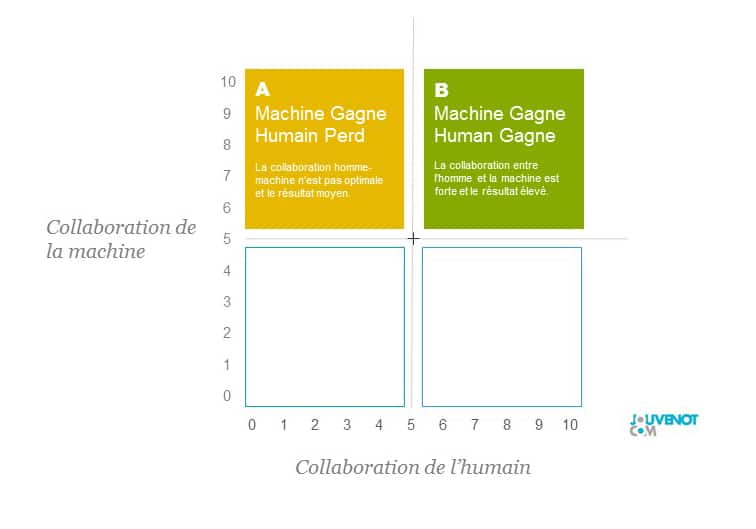
Dans le carré A, situé en haut à gauche (de la figure ci-dessous), la collaboration n’est pas optimale puisque la collaboration de l’humain n’est pas totale, qu’il en soit d’ailleurs responsable ou non. Il en ressort une combinaison asymétrique dans laquelle la machine tire un avantage au détriment de l’homme.
Dans le carré B, situé en haut à droite (de la figure ci-dessous), la collaboration est optimale puisque l’humain et la machine collaborent l’un et l’autre pleinement, en synergie. Il en ressort un résultat maximisé.
Dans le carré C, situé en bas à gauche (de la figure ci-dessous), la collaboration n’est pas optimale puisque la machine ne collabore pas réellement. Il en ressort une combinaison asymétrique dans laquelle l’homme tire un avantage au détriment de la machine.
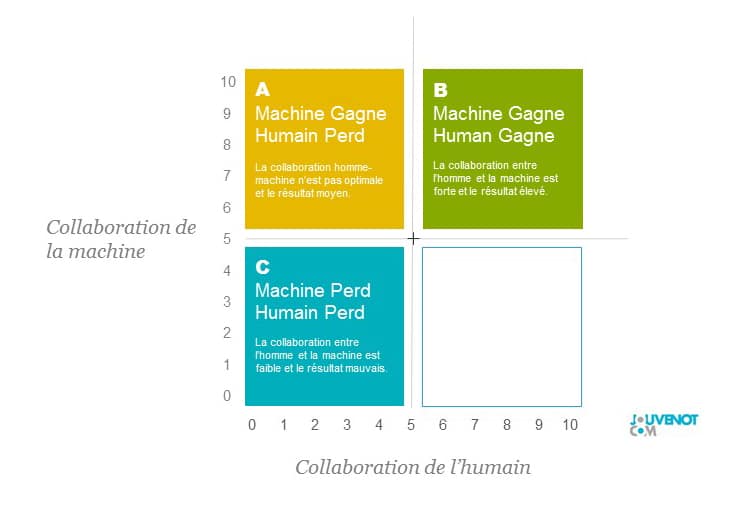
Dans le carré D, situé en bas à droite (de la figure ci-dessous), la collaboration n’est pas optimale puisque ni la machine ni l’homme ne collaborent pleinement. Il en ressort un résultat minimisé qui pénalise les deux protagonistes.
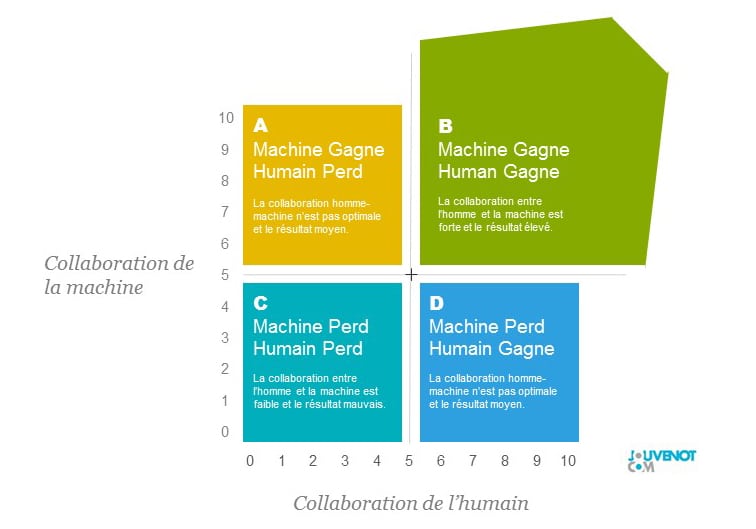
Un scénario idéal
Le scénario idéal est naturellement celui où l’homme et la machine sont en synergie, pour le plus grand bénéfice de l’un et de l’autre, au point de parvenir ensemble, non seulement à produire un résultat qui n’aurait pas pu être obtenu autrement, mais également un résultat qui n’avait pas été envisagé préalablement.
La nécessaire détermination de la nature de la collaboration
Ceci étant posé, il convient à présent de définir la collaboration de l’homme vis à vis de la machine, puis de la machine vis-à-vis de l’humain et enfin, leur effort mutuel.
L’effort de collaboration de l’homme avec la machine
Douze critères peuvent permettre d’évaluer la collaboration de l’homme vis-à-vis de la machine au sein de cette relation homme-machine :

Ainsi, l’humain :
- Se comporte comme un maître donnant des instructions à un serviteur, tout en écoutant, malgré tout, ses remarques d’expert.
2. Considère l’algorithme comme un travailleur et se comporte lui-même comme un manager (précisant les objectifs, recueillant des feedbacks, prenant des décisions…).
3. Fournit des instructions claires et non ambiguës.
4. S’efforce de comprendre la propre logique de l’algorithme ainsi que ses progrès spécifiques.
5. Utilise au moins 25% des capacités de l’algorithme.
6. Admet qu’il n’est pas capable d’envisager toutes les contingences possibles.
7. Utilise un système d’alertes pour réguler l’équilibre du pouvoir entre l’homme et la machine.
8. Appréhende l’algorithme avec un esprit ouvert, sans agenda caché, sans peur ni préjugé.
9. Se manage lui-même (stress, fatigue, doute, échecs, épuisement…).
10. Se benchmark lui-même avec d’autres humains vivant la même expérience.
11. Evite d’entrer en compétition avec l’algorithme.
12. Revoit constamment ses hypothèses au sujet du comportement de l’algorithme.
L’effort de collaboration de la machine avec l’humain
Dix critères peuvent permettre de mesurer le degré de collaboration de l’algorithme vis-à-vis de la machine, au sein de cette relation homme-machine :

Ainsi, la machine :
- Suit scrupuleusement les trois règles de la cybernétique :
a/ un robot ne peut porter atteinte à un être humain, ni, en restant passif, permettre qu’un être humain soit exposé au danger ;
b/ un robot doit obéir aux ordres qui lui sont donnés par un être humain, sauf si de tels ordres entrent en conflit avec la première loi ;
c/ un robot doit protéger son existence tant que cette protection n’entre pas en conflit avec la première ou la deuxième loi.
Le mot « atteinte » n’est pas ici limité à une acception étroite qui n’évoquerait que d’éventuelles atteintes physiques, mais à une signification englobant également des possibles atteintes physiques (déstabilisation, harcèlement, burn out…).
2. Dispose d’un ensemble de règles de fonctionnement connues, actualisées, claires et compréhensibles par quiconque.
3. Fournit des données claires, en temps réel, au sujet des progrès de l’homme, de ses propres progrès et de leurs progrès communs.
4. S’adapte à l’homme.
5. Respecte la spécificité de l’utilisateur (prédispositions, niveau, préférences intellectuelles, traits psychologiques majeurs…).
6. Fournit régulièrement des propositions, ou contre-propositions, au sujet du travail effectué en commun, en expliquant pourquoi.
7. S’adapte au rythme de l’utilisateur dans le temps.
8. Prend en compte le fait que les données sur lesquelles il s’appuie peuvent être biaisées.
9. Gère, en toute transparence, l’équilibre entre unsupervised learning, supervised learning et reinforced learning.
10. Effectue des ajustements en continu pour produire le résultat visé.
L’effort de collaboration mutuelle de l’homme et de la machine
En complément, douze critères peuvent permettre de mesurer le degré de collaboration relevant autant de l’homme que de l’algorithme dans cette relation homme-machine :

Ainsi, l’homme et la machine :
- Sont d’accord pour réaliser ensemble des sessions de feedback afin d’apprendre ensemble.
2. Partagent une compréhension commune du résultat visé.
3. Mesurent et déterminent en temps réel si le résultat est en cours de réalisation.
4. Réalisent périodiquement des analyses plus approfondies pour évaluer si l’algorithme se comporte conformément aux attentes.
5. Comparent leur propre collaboration avec d’autres binômes hommes-machines.
6. S’efforcent de comprendre en profondeur leurs préférences, leurs modes d’apprentissages, leurs modes de travail, leurs forces et leurs faiblesses respectives.
7. Font preuve d’assertivité.
8. Ont des attentes réalistes et raisonnables vis-à-vis l’un de l’autre.
9. Ne cherchent pas à être meilleur que l’autre dans un domaine où l’autre est précisément le meilleur.
10. Déterminent ensemble le meilleur compromis entre les données nécessaires à l’algorithme pour opérer et les besoins de confidentialité ou de respect de la vie privée de l’homme.
11. Planifient une rééducation de l’algorithme en cas de divergence, de déviance, d’écart entre les attentes et les résultats.
12. Visent une asymétrie de l’information proche de zéro.
Le besoin d’une méthode simple mais robuste
Une fois posés, les critères permettant l’évaluer le niveau de collaboration entre l’homme et une, ou plusieurs, intelligences artificielles, peuvent faire l’objet d’une mesure rigoureuse par un système de notation simple, sur une échelle allant de un à dix (un étant le niveau le plus bas de satisfaction du critère et dix son niveau le plus élevé).


La notation, quant à elle, pourra s’effectuer selon différentes modalités :
- L’auto-évaluation : la notation est effectuée par l’homme impliqué dans cette relation homme-machine.
- L’évaluation : la notation est effectuée par une autre personne externe et objective (évaluation).
- L’évaluation automatisée : la notation est effectuée par la machine uniquement.
- L’évaluation symbiotique : la notation est faite par l’homme et la machine (au cours de leurs séances d’évaluations respectives notamment (cf. critères 3 et 4 de la rubrique « La nécessaire collaboration mutuelle » ci-avant).
- L’évaluation statistique : la notation provient d’une comparaison avec des relations hommes-machines similaires.
Nous ne nous prononçons pas davantage sur les forces et les faiblesses de ces différentes options, préférant laisser à d’autres experts plus aguerris sur ce point méthodologique précis, le soin de s’exprimer à son sujet.
Usages possibles
Par-delà l’analyse ponctuelle de quelques algorithmes, il convient d’identifier les utilisations possibles de cette matrice à plus long terme. Voici donc une première série d’usages envisageables :
Dans le cadre du développement informatique, les codeurs sont de plus en plus confrontés à une intelligence artificielle ou à des algorithmes qu’ils développent, enrichissent, maintiennent, étudient, utilisent, subissent.
Dans des environnements industriels ou logistiques, dans lesquels les hommes ne sont plus des OS2 depuis longtemps et travaillent de plus en plus avec des robots toujours plus intelligents.
Dans le secteur du digital, naturellement, au sein duquel le service proposé par de nombreuses start-up repose largement sur des algorithmes que les salariés de l’entreprise managent et traitent finalement comme des travailleurs, des collaborateurs, une nouvelle génération de collègues, en somme.
Pour les ressources humaines et les managers soucieux de production, de productivité, de bien-être au travail, de marque employeur et qui voient de plus en plus leurs équipes ou collaborateurs interagir directement ou indirectement avec des algorithmes (cachés derrière les applications qu’ils utilisent, par exemple).
Pour les politiques confrontés à des phénomènes inédits comme Google (qui touche à la connaissance) ou Airbnb et consort (qui uberisent des secteurs réglementés), ou d’autres, qui influent sur la cybersécurité, ou la cyberdélinquance…
Pour le législateur devant déterminer la responsabilité des uns ou des autres, par exemple, dans le cadre d’un accident causé par une voiture autonome, conduite par un algorithme, qui sont les responsables? Le chauffeur à bord qui n’a pas utilisé le mode manuel, le constructeur du véhicule, le développeur de son algorithme, etc. ?
Dans le domaine de la santé, où les patients laissent de plus en plus des machines collecter des données sur eux, face à un corps médical dont le métier est littéralement colonisé par les nouvelles technologies…
Dans l’éducation, où l’on sait qu’une partie du succès revient au travail personnel de celui qui reçoit un enseignement, dans un monde où chaque élève recourt de plus en plus à Wikipedia, Google et consorts pour se documenter.
Etc.
Précautions
L’utilisation de cette matrice devra néanmoins être assortie de précautions. Elles auront tantôt des origines scientifiques, méthodologiques ou pratiques. Parmi les principales, nous pouvons déjà mentionner celles qui figurent ci-dessous :
Le caractère mouvant et hyper évolutif dans lequel fonctionnent les algorithmes (le digital) rendent toute conclusion à leur sujet susceptible d’être frappée d’obsolescence ou même tout simplement invalidée.
La plus ou moins grande perméabilité des individus face aux machines est un élément à prendre en compte. Il est clair qu’un critère comme la génération de l’individu influencera sur la collaboration homme-machine, celui de la nationalité également (les français sont particulièrement sensibles aux questions relatives à la vie privée, à la confidentialité des données, etc. là où les chinois le sont beaucoup moins).
La jeunesse des algorithmes étudiés est aussi à prendre en considération. Rappelons qu’ils ont été développés vite, dans des environnements eux-mêmes nouveaux, avec des technologies émergentes. Il serait donc malvenus de tirer des conclusions trop sévères ou trop hâtives à leur endroit.
L’opacité des entreprises qui éditent ces algorithmes, souvent entourés de beaucoup de secret, est un facteur déterminant dans la véracité de l’analyse.
Les biais liés à la qualité et la fiabilité des données utilisées par l’algorithme sont un élément crucial qui influence nécessairement leur efficience.
La propension de l’homme à demander aux algorithmes de lui ressembler en produisant une intelligence (artificielle) ressemblant par certains aspects à la sienne propre, plutôt qu’à lui être différente, voire étrangère. Rappelons que c’est lorsqu’il a cessé de copier la nature, et notamment les oiseaux, que l’homme a trouvé la solution pour faire voler des avions, qui n’ont aujourd’hui plus rien à voir avec un quelconque animal volant.
La maturité des algorithmes, qui sont encore dans leur propre enfance, sachant qu’ils grandiront peut-être trop vite du fait de leur capacité d’auto-apprentissage hyper rapide, est aussi à garder en tête.
Prochaines étapes
La fécondité de cette première réflexion est établie. Vous l’aurez compris, la démarche est spéculative, ouverte, en cours et ressemble à de la peinture fraîche. Rien de définitif ici, puisque nous sommes dans le monde digital, où l’open innovation est désormais une réalité, la collaboration transverse, une possibilité et la mise à jour, une nécessité perpétuelle.
Place à présent au crowdsourcing avec vos contributions et vos commentaires que nous attendons. Si des machines se sentent capables d’apporter leur pierre à l’édifice, elles sont plus que les bienvenues.
Les témoignages, les réactions, les enrichissements intellectuels, les dons ou la mise à disposition de ressources (machines, cerveaux, labs, etc.) sont également bienvenus.
Remerciements
Nous tenons à remercier ici quelques auteurs dont les ouvrages ont largement favorisé l’élaboration de cette matrice : Tim O’Reilly, Kevin Kelly, Simon Head, Erik Brynjolfsson, Andrew Mcafee, Salim Ismail, Michael Malone, Peter Thiel, Black Masters, Scott Galloway…
Bertrand Jouvenot | Consultant | Auteur | Speaker | Enseignant | Blogueur